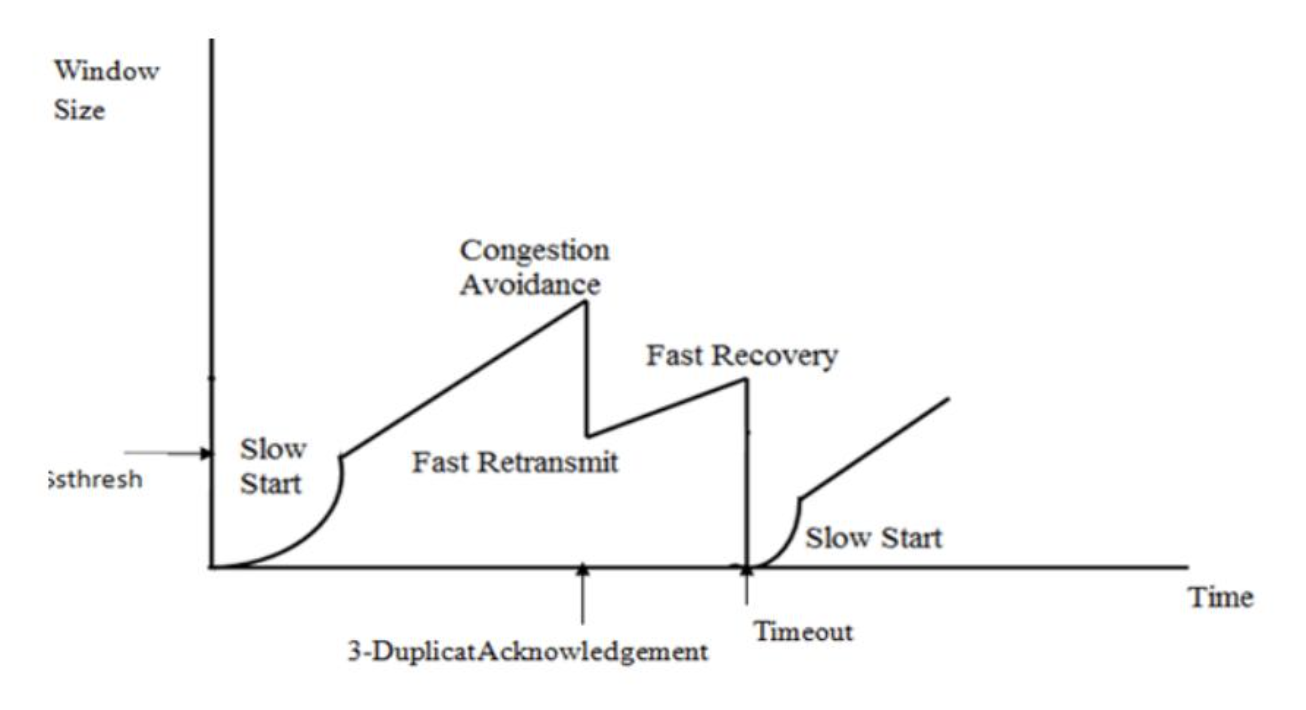
TCP拥塞控制算法的前世与今生
写在前面
TCP协议(Transmission Control Protocol,传输控制协议),诞生于 1974 年,算得上是最古老且最复杂的网络协议之一,但同时其又处于动态发展之中。尽管,许多重要的改进被提出和实施,但 TCP 的基础内容,即发表于 1981 年的标准 RFC793 中规定的许多基本操作并没有做较大的改动。
后续的改动主要围绕拥塞控制展开,这也是 TCP 协议区分于 UDP 协议的一个重要方面,TCP 协议不仅提供可靠的传输,还提供拥塞控制机制。
拥塞控制考虑整个网络的拥塞情况,网络拥堵时,TCP 包无法到达,进行重传,进一步加重拥堵,所以在网络拥塞时,需要发送方调整发送速率,避免发送方的发送的数据填满整个网络,加重网络负担。在拥塞控制的同时,还需要确保公平。
一、TCP 拥塞控制的基本机制
谈 TCP 的拥塞控制,虽然你可能听过 Tahoe、Reno、Vegas、Cubic、Westwood 以及 BBR 等术语,这些都是适用于不同场景的具体算法。但是 TCP 拥塞控制的基本机制逃不开以下 4 个,具体的算法大多是在处理丢包问题上有所区别。
TCP 通信中,在发送窗口 swnd 和 接收窗口 rwnd 的基础上,又新增了一个拥塞窗口 cwnd ,由发送方维护,来限制可能在端到端通信间传输的未确认分组的总数。
1.1 Slow Start 慢启动
慢启动指的是从较低的初始值开始,以指数速率增长:当每个分段得到确认时,拥塞窗口会增加一个 MSS(Maximum segment size),使得在每次往返时间(Round-trip time,RTT)内拥塞窗口能高效地成倍增长。
慢启动解决了什么?试想如果拥塞窗口无法快速增长,互联网注定会在海量的突发数据传输之下不堪重负。
1.2 Congestion Avoidance 拥塞避免
拥塞避免指的是当达到慢启动门限后,拥塞窗口转为线性增长;当每个分段得到确认时,拥塞窗口会增加 ,使得在每个 RTT 内拥塞窗口线性增长。这就是加法增(Additive Increase,AI)的思想。
而当拥塞发生时,即检测到丢包时,拥塞窗口积式减小,这就是乘法减(Multiplicative Decrease,MD)的思想。
课堂上是这么教的没错,并且你可能习惯性地把这里的每一个数据包的大小都当作“1”,与数据链路层的滑动窗口协议就差不多了并且很好理解。看似问题不大,但是,TCP 中,发送端根据收到 ACK 报文的数量来调整拥塞窗口,把每个数据包的大小都是 1 个 MSS ,但这并不是根据 ACK 实际应答的数据长度来反馈的。
试想持续发小包的情形(你可能觉得 Nagle 算法会帮你解决这个问题,实则不然,像 Telnet、SSH 等每个数据包仅几个字节,仍会保持小报文流传输):
- 每个 ACK 只“确认”很少数据;
- cwnd 仍然按 1/cwnd 个 MSS 增加;
此时问题就来了,即使 ACK 只确认了 10 个字节,也可能导致增加 1 个 MSS 的 cwnd,这会高估网络容量,如果之后传输过程需要发送大量数据包,就可能造成严重丢包。
那么,你可能又会问了,课堂上不是说了,TCP 有 Delayed ACK 机制,不需要对每个数据包都发送 ACK 确认帧,多个较大的 TCP 报文使用一个 ACK 应答,比如,1 个 ACK 确认 2 个 MSS,却只让 cwnd 增加了 1/cwnd 个 MSS,低估了链路能力,又会使得发送端拥塞窗口增加地较慢,影响 TCP 的传输性能。
更合适的方法是标准 RFC 3465 中提出的 Appropriate Byte Counting,就简称 ABC 机制吧。我将单开一节叙述。
1.3 Fast Retransmit 快速重传
这是 TCP 中用于加速重传采用的一种特殊机制。一般的分组需要等待计时器超时才进行重传,而快速重传基于以下机制:连续收到 3 个冗余 ACK 就判断丢包,立即重传。
1.4 Fast Recovery 快速恢复
快速恢复事实上是与快速重传搭配使用的。快速恢复事实上是在 TCP Reno 中才被引入的,其机制是:丢包后不回到起点,而是适度减小 ,保持传输活性。适用于丢包不是很严重的场景。
二、适当的字节计数 ABC 机制
2.1 Slow Start 慢启动
在慢启动阶段,ABC 增设了一个限制 ,按照 RFC 3456 ,其建议值是 ( 是 Sender MSS),TCP 发送方应将 cwnd 增加每个传入确认确认的先前未确认的字节数,但是不能超过 ;建议值比 RFC 2581(相当于 更加激进),但同时抵消了 Delayed ACK 带来的影响,相当于为接收方由于启用延迟确认而保留的确认帧也增加 。
不过例外是当 RTO 超时时,即发生丢包时,此时发送方需要重传对应的数据包。考虑以下例子:
- 发送方:N(丢失),N+1(成功),N+2(成功);
- 发送方收到 2 个重复的 ACK ;(还未满足 DACK)
- 发送方等待 RTO 超时后,重传数据包 N ;
- 当 N 被重传并成功送达,接收端会立即发出一个 ACK = N+2 ;
- 发送方收到该 ACK ,一下子确认了 N ~ N+2 3 个数据包;
- 但此 ACK 并不表示在上一个 RTT 中有三个分段离开了网络,真实情况是只有一个分段离开了网络;
- 发送方不能仍按照倍数增长;
因为 RTO 后的 ACK 不再可靠地表示「链路真正吞吐能力」,而可能是积压 ACK 的“报复性到达”,ABC 如果直接采用这些 ACK 的“确认字节数”,就可能高估网络容量、加快增长速度、触发新一轮拥塞。所以 RTO 后,ABC 机制“退回”到保守的每 ACK 增长 1 SMSS。
2.2 Congestion Avoidance 拥塞避免
ABC 机制将已确认的字节数存储在 bytes_acked 变量中,当 bytes_acked 达到 cwnd 时,窗口增加 1 个 SMSS ,bytes_acked -= cwnd 。
三、具体实现算法的演进
具体实现算法事实不少,这里仅介绍几个非常典型的。
3.1 基于丢包
3.1.1 TCP Reno && TCP NewReno
现在距离 TCP Reno 的时代已经距离非常之久了,虽然但是教材上讲的还是 TCP Reno ,主要就是因为 4 个基本机制基本都是由它最先确定的,它们也是基于丢包的拥塞控制算法的典型代表。
TCP Reno 有什么问题?它采用 AIMD 的方式,试想理想信道中只有一条 TCP 流,那么理论上根据 AI ,cwnd 会无限增长下去。这没什么问题,但如果多条 TCP 流共享信道呢?这时候就会产生拥塞了,当然也可以从带宽的角度理解,带宽就相当于水管的横截面积,两个 TCP 流都保持原有的带宽,但这个网络管道需要均分带宽,这就是拥塞。
显然,Reno 并不知道带宽,并且如果此时 cwnd 已经很大了,即使执行了 MD ,带宽仍大于实际可用,拥塞仍在进一步加剧。
所以最好就是把拥塞窗口维持在刚好够用的状态,避免其无限制增大。对于理解带宽这一点,事实上要等到 Google 的 BBR 算法。而 Reno 以及 NewReno 都没有解决带宽估计问题。
相较于 TCP Reno ,TCP NewReno 改进了丢包恢复机制。我们知道,对于 Reno ,TCP Reno 能处理一个丢失的数据包:当收到 3 个重复 ACK 后,触发快速重传,进入 Fast Recovery 阶段。但如果窗口存在多个丢包,那么重复 ACK 只能触发第一个数据包进行重传,后续的丢包需要等待 RTO 超时,代价较高。
TCP NewReno 引入了 Partial ACK 机制(一个 ACK 只确认了部分数据,并非整个窗口),NewReno 利用这个信号,主动立即重传下一个推测丢失的数据包,而不等 3 个重复 ACK。
还是实际的场景比较好理解,看下图吧。

初始发送窗口包含 Data[0] ~ Data[11] 共 12 个数据包,其中 Data[1] 和 Data[4] 发生丢包。
- 发生第一个快速重传:收到 3 个 dupACK[0],重传 Data[1];
- 收到 Partial ACK = 3 :重传 Data[4],同时再发送一个新包;
- 为什么这里不等待 3 个重复 ACK 呢?因为如果刚刚 Data[4] 没丢,那么,重传的 Data[1] 如果正确收到了,接收方会直接回 ACK[12] 而不是 ACK[3];
- 后续收到的每个 dupACK 都会驱动发送一个新包;
即,TCP NewReno 无需等待 RTO 超时,且在快速恢复阶段,每个 ACK(dup 或 partial)都驱动新的数据发送。
| RTT | 发出 | 包括重传 |
|---|---|---|
| 第 1 RTT | Data[0]~[11] | - |
| 第 2 RTT | Data[12]~[15], 重传 Data[1] | 5 包 |
| 第 3 RTT | Data[16]~[20], 重传 Data[4] | 6 包 |
| 第 4 RTT | Data[21]~[26] | 6 包 |
从上表可见,在 4 个 RTT 内,NewReno 成功重传并恢复窗口,只错过一个数据包(比 Reno 快很多)。
3.1.2 TCP BIC && Cubic
TCP Cubic 也是现在广泛采用的拥塞控制算法之一,TCP Cubic 作出的改进主要是在 cwnd 的恢复上,由 TCP Reno 的线性增长,再到 TCP BIC 使用二分搜索算法尝试找到能长时间保持拥塞窗口最大值的值,TCP Cubic 使用三次函数代替二分算法作为其拥塞窗口算法,并且使用函数拐点作为拥塞窗口的设置值,Linux 内核在 2.6.19 后使用该算法作为默认 TCP 拥塞算法。
首先,思考一下为什么在 Reno 之后诞生了 BIC 和 Cubic 。Reno 存在的问题就是,当发生快速恢复后, ;注意此时并没有重新回到慢启动,而是处于拥塞避免状态,一个 RTT 内 cwnd 只加 1 ,如果对于 RTT 特别长的情况,比如卫星通信,那么要很长时间才能恢复到最佳的拥塞窗口,可以看下面这个经典老图。
TCP BIC
TCP BIC 的二分搜索如何操作呢?首先,乘法减的思路是不变的,当发送快速重传时, ,最佳的搜索窗口 应该在 区间内,怎么找呢?那就是二分搜索了,可以看下面这张图:
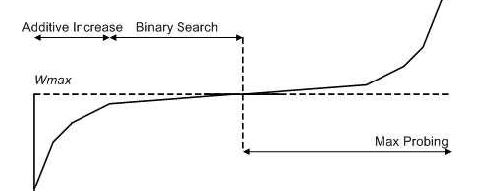
左边部分就是二分搜索的过程,可以看到增加窗口的过程是一个上凸函数,如果 在 附近,窗口能快速增长,在靠近 放缓,快速收敛到 ;如果 在 附近,一开始快速增长可能导致错过 ,但这并没有关系,当触发下一次增窗时,也能最终收敛到 。
右边部分的 Max Probing 部分是在做什么呢?如果增窗时超过 ,那么发送方有理由认为可能是网络环境变好了,就继续慢慢增长窗口尝试能否抢占更多的网络资源(慢是为了兼顾公平性,不是事实上是否实现了真正的公平还有待商榷),然后越来越快,保证快速收敛。这个过程被称为最大窗探测。
TCP Cubic
那我问你,TCP BIC 就一点问题没有了吗,回到它的设计之初,是为了解决 RTT 较大、丢包率较高的网络环境中增窗过慢的问题,那它适用于 RTT 较小、丢包率较高的环境吗?
TCP BIC 的增窗对于这种环境来说显然有些过于激进了,并且也存在公平性方面的问题(事实上最大窗探测部分的协议实现也较为复杂,上面我只阐述了基本思想)。所以又造出了 TCP Cubic ,它把 RTT 独立出来,对 RTT 不敏感,而引入时间步长来解决 BIC 存在的问题:
Cubic 和 BIC 在乘法减的过程是类似的,当快速恢复发生时, ,而 就是 ,代入就可以求出 ;
到这里 Cubic 事实上就差不多结束了, 和 就是用来控制性能和公平性的。具体设置此处不过多展开了。
3.1.3 基于丢包的算法(AIMD)为什么能实现公平性?
考虑以下情形: 个流复用同一个网络,并设它们在网络过载的瞬时时刻的拥塞窗口分别为 ;
所以,整个网络能容纳的数据包量 ; 也等于单流独占网络时的最大拥塞窗口值。
现在,由于网络过载,每个流都开始丢包,执行 MD 策略,窗口均减小为 ;而此时网络空闲的窗口数为 。
接着,每条流开始执行 AI ,均分空闲窗口,即每个流增加的窗口数为 。
第二次感知到丢包,每条流的窗口变为 ;
第三次感知到丢包,每条流的窗口变为 ;
第 次感知到丢包,每条流的窗口变为 ;
依次代入可得 ;
最终,有:
如此,当我们有 条流,每一条流分得 的带宽,这就是 AIMD 算法保证的公平性。
3.1.4 Buffer 和基于丢包的拥塞控制算法
先说结论,基于丢包的拥塞控制必然会使用到缓冲区,如果要实现高吞吐量必然会导致排队延迟。
试想如果多条流复用同一个网络,网络管道必然会过载,此时需要需要引入部署在交换节点 Buffer 来暂存过载的数据包,如果没有 Buffer,网络将退化到 CSMA/CD 总线,丢弃所有过载的数据包。而这些拥塞控制算法是如何知道丢包的呢?只有当数据真的把路由器/交换机的缓冲区塞满,才会发生丢包!
而想要用这种方式“试探”最大吞吐量,必须让数据堆积在 Buffer 中,直到丢包发生为止。缓冲区一满,延迟自然增加:
- 数据包需要排队等待前面数据被发送;
- 越多的数据排队 越高的排队延迟;
- 延迟再加上传播 RTT 应用层体验显著下降;
这就是 Bufferbloat(缓冲膨胀) 现象。
3.2 基于延迟 —— BBR 算法
3.2.1 BBR 的基本原理
在介绍 BBR 算法对具体机制之前,先在简单回顾一下基于丢包的几种算法,只依靠丢失数据包的迹象作为减缓发送速率的信号。效果固然还不错,Cubic 沿用至今,至于教科书上讲的 TCP Reno 只是一个兜底的收敛算法,对带宽利用率豪无保证,甚至 50% 都达不到(乐)。总而言之基于丢包的算法都无法兼顾效率。但网络环境的巨大变化(主要是带宽的巨大提升,以及网络质量越来越好,丢包率低),亟待算法能够最大化利用带宽。这时候,BBR 算法就横空出世了。TCP BBR(Bottleneck Bandwidth and Round-trip propagation time)由 Google 设计,于 2016 年发布。
之前的算法无法兼顾效率的原因是,各种算法都将网络看成了一个容器而不知道什么是带宽。 的单位是数据包的个数,而带宽的单位则是单位时间内发送数据包的个数。
BBR 算法的核心是找到 瓶颈带宽(bottleneck bandwidth, BtlBw)和最小延时(Min RTT) 这两个参数,最大带宽和最小延时的乘积可以得到 BDP (Bandwidth Delay Product,带宽时延积), 而 BDP 就是网络链路中可以存放数据的最大容量。
然后,BDP 驱动 Probing State Machine(探测状态机)得到 pacing rate(一窗数据的数据包之间,以多大的时间间隔发送出去)和 cwnd,分别设置到发送引擎中就可以解决发送速度和数据量的问题。
3.2.2 BBR 的状态机
1. Startup(启动)
- 快速指数增长发送速率,直到发现带宽饱和(Throughput 不再增加)
- 探测出 BtlBw 之后,BBR 转入 Drain 状态
2. Drain(排空)
- 启动阶段可能造成 cwnd > BDP,导致 bufferbloat
- Drain 阶段通过减小速率,让 flight size 降回 BDP 水平,然后转入 ProbeBW 状态
3. ProbeBW(带宽探测)
- 稳定工作阶段
- 继续计算当前的瞬时带宽,并据此计算 pacing rate 和 cwnd ;
4. ProbeRTT(延迟探测)
- 每隔一段时间(默认 10s)暂停发送几毫秒,测量路径最小 RTT
- 防止 bufferbloat 掩盖真实延迟
注意:BBR 算法的状态机事实上并不影响 RTT 和 BtlBw 的测量,不同状态只影响增益系数的计算,具体见下一节。
Linux 内核中有关代码如下:
1 | |
3.2.3 RTT 的测算
TCP BBR 对 RTT 进行跟踪,并作出一定的估计,设在任意时刻 :
其中:
- ,表示路径上因为积压、接收方延迟应答策略、应答聚合等因素而引入的 “噪声” ;
- 表示路径的往返传播时延,这是物理特性,只依赖于链路长度和链路速率,只有当路径发生变化时其值才会发生改变(“路径的物理最小 RTT”,即网络上没有任何排队时的最短传播时延);
在时刻 ,对 的一个无偏、高效估计是:
也就是说:BBR 在过去一段时间窗口 内,取 RTT 的最小值作为 RTprop 的估计。
取这段时间内的最小值,最有可能是“没有排队时的 RTT”,即真实 RTprop ,所以是无偏估计,且这是可测量的,算法简单!
3.2.4 瓶颈带宽 BtlBw 的测算
RTT 在 Linux 内核中就有跟踪和计算相关的方法,而 BtlBw 是 BBR 算法全新出厂的,虽然没有办法直接知道路径上实际的 BtlBw,但可以通过接收到的 ACK 到达速率(delivery rate)推断出 BtlBw 。
其中:
- 表示某段时间内成功确认的字节数;
- 表示这些字节的 ACK 到达间隔,并且 ,因为可能会出现 ACK group / 网络波动 / ACK delay ;
所以 ;即估计出的传输速率不会超过真实瓶颈带宽,因此 BtlBw 在一段时间窗口 内的一个高效且无偏的估计为:
这里的 一般等于 6 ~ 10 个 RTT 。
3.2.5 Pacing Rate 与 cwnd 的计算
Pacing Rate 默认采用在 10 个 RTT 时间窗口内的最大 BtlBw 乘以增益系数,增益系数与状态机所处的状态有关。
cwnd 由 BDP 乘以 cwnd 的增益系数计算得出,而 BDP 可以根据最小 RTT 计算得出。
这里就不继续展开过多细节了,事实上 BBR 在发送数据包和接收 ACK 时的处理逻辑并没有说的这么简单,等以后有时间再展开吧,这里先把基本逻辑说清了。
3.2.6 BBR 算法与 Buffer
BBR 算法不希望产生积压,或者说 TCP BBR 并不会占用到缓冲区(或者很少),更多是基于带宽速率进行判断,使 ,即最小化缓冲区积压,也等价于最高吞吐 + 最低延迟,这需要做到速率平衡和管道填满:
- 速率平衡(rate balance):瓶颈链路的数据包到达速率刚好等于瓶颈带宽 BtlBw ,保证了链路瓶颈已达到 100% 利用率。
- 管道填满(full pipe):传输中的总数据(inflight)等于 BDP ,保证了有恰好足够的数据,既不会产生瓶颈饥饿(bottleneck starvation),又不会产生管道溢出(overfill the pipe)。
如果只测算 BtlBw ,那只能保证速率平衡,试想:某个连接在一个 的链路上,开始时它发送了 10 个包的窗口,之后就一直稳定运行在瓶颈速率上。那么,在这个链路此后的行为就是:
- 稳定运行在瓶颈速率上;
- 稳定有 5 个包的积压(在 Buffer 中排队);
如果只满足管道填满,但是不保证速率平衡,那管道填满的状态并不能持续。试想,如果某个连接以 的突发方式发送一个 BDP 的数据,那仍然能达到瓶颈利用率,但却会产生平均 的瓶颈积压。
例子可能不是很好理解,再解释一下,如果在很短的时间()内,把一个 BDP 的数据全都“突发”发送出去,但此时瓶颈链路每秒只能发送 BtlBw 的速率,所以这段时间内只能处理 的数据,平均积压是 。
3.2.7 MIMD 与公平性
通过上面的分析,我们可以发现,BBR 算法采用的是 MIMD ,能够更快地完成 BtlBw 建模和反应瓶颈变化。但是,MIMD 会导致本来速率高的流加得更多,减得也更多,但下降之后也比别人快,可能造成速率低的流成长慢、抢不到带宽,公平性是脆弱的。这也是 BBRv1 饱受争议的一个点,公平性的问题在 BBRv2 中得到了改进。
3.2.8 TCP BBR vs. Cubic
BBR 与 BDP 呈现正相关,与缓冲区大小呈现负相关,而 Cubic 恰恰相反。具体内容等后续补充。
写在后面 —— 关于设计拥塞控制算法的一些思考
从 Reno 到 Cubic ,再到现在的 BBR 算法,可以发现后者都是在前者的问题上或者根据网络环境的变化而改进,增添了更多机制或者采集了更多环境信息。如果从信息论的角度理解,是否可以认为一个好的拥塞控制算法就是能收集和利用更多的信息,降低信息熵?
一种方向是增加更多的信息(主要是在 ACK 中增加),比如 DCTCP 在交换机中增加 ECN 标志,抑或是 HPCC 更进一步在交换机中设置更多信息给发送端。
另一种方向那就是基于统计学的思想,采集大量的信息总结出可能的规律,拟合出网络的某些模式或特征,或者找出现有算法的 Bad Case ,但是需要收集大量的数据和较长的迭代周期。
另外,评价拥塞控制算法好坏的标准又是什么呢?零丢包?高带宽?快速收敛?公平性?如何达到这些需求,或者兼顾,而诞生出百花齐放的各种 CC 算法。归根结底,TCP 的拥塞控制算法是为应用层服务的,流量往往是波动的,实际情况可能是突发流量,或者流量根本达不到满载状态。说白了,发展到现在,“动态响应性能”才是最需要关注的。