Chapter1 概论
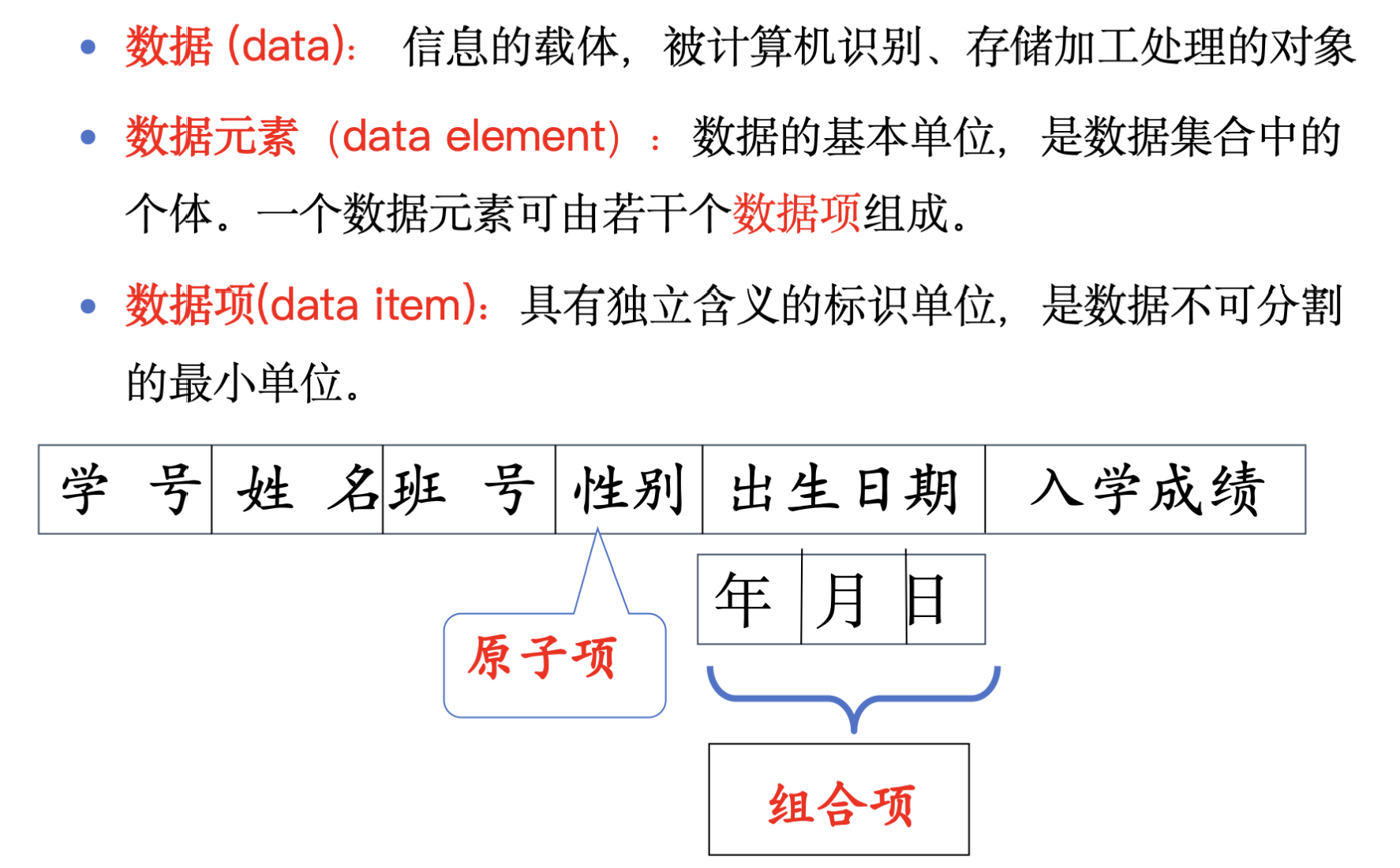
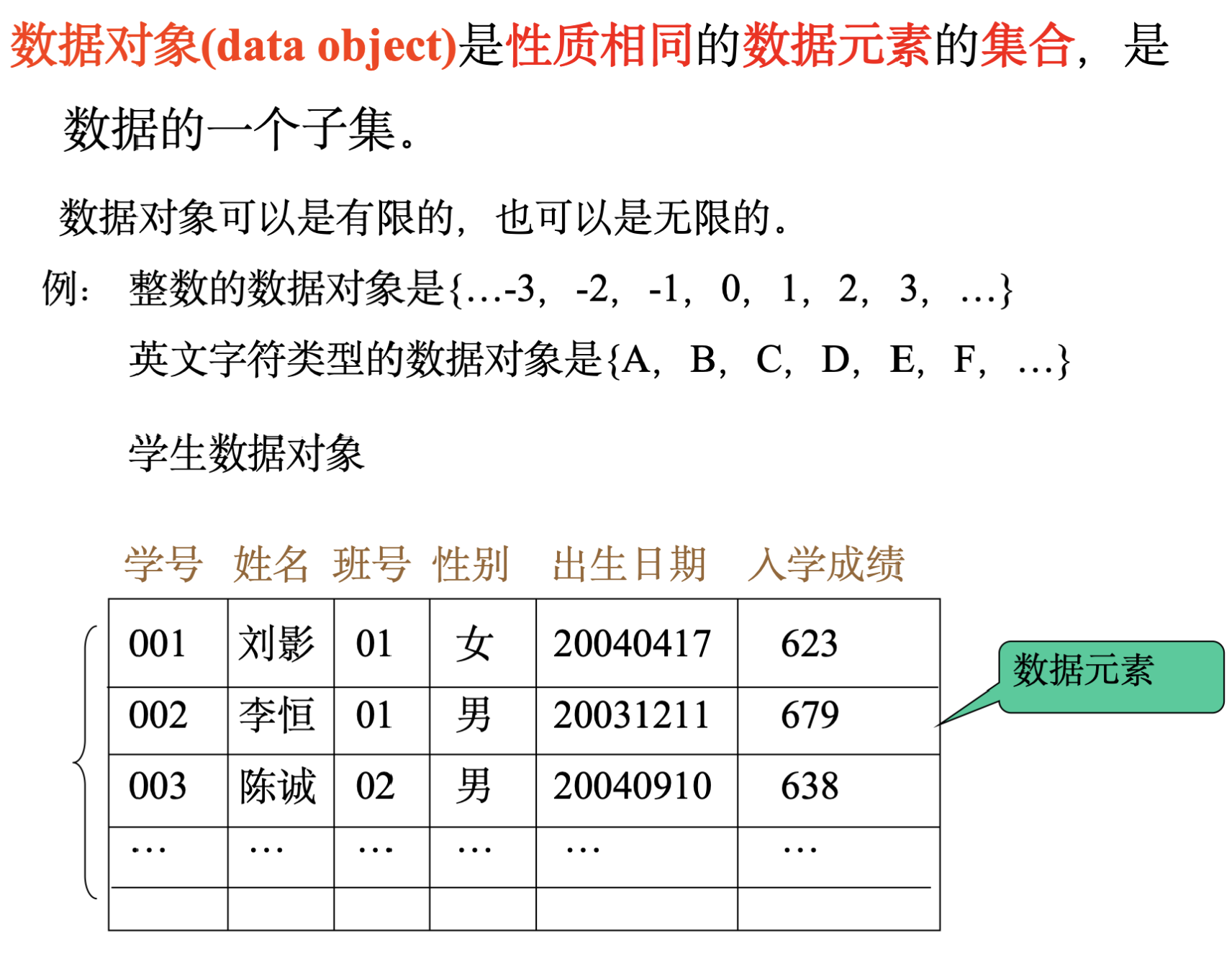
数据、数据元素、数据项、数据对象、数据结构等基本概念
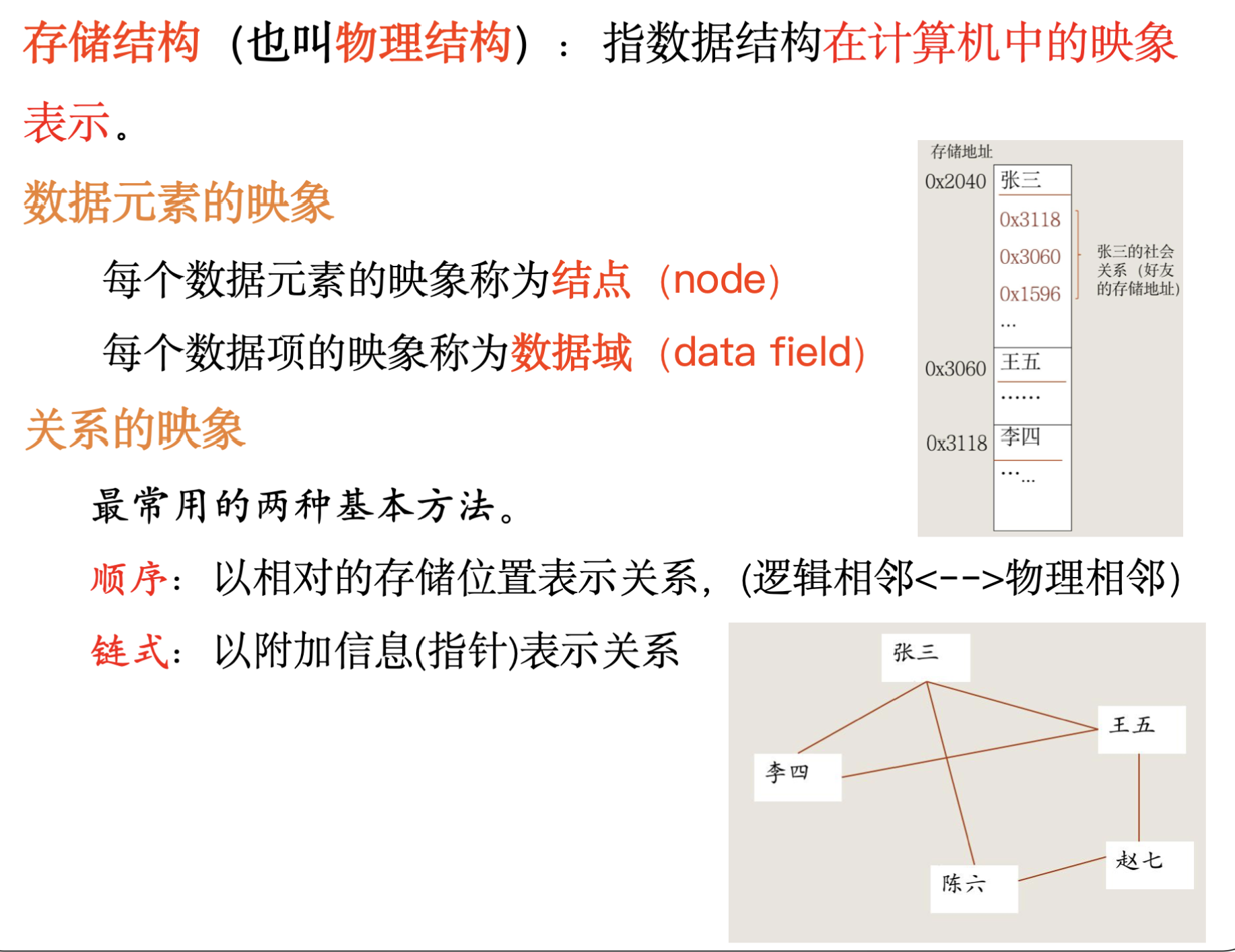
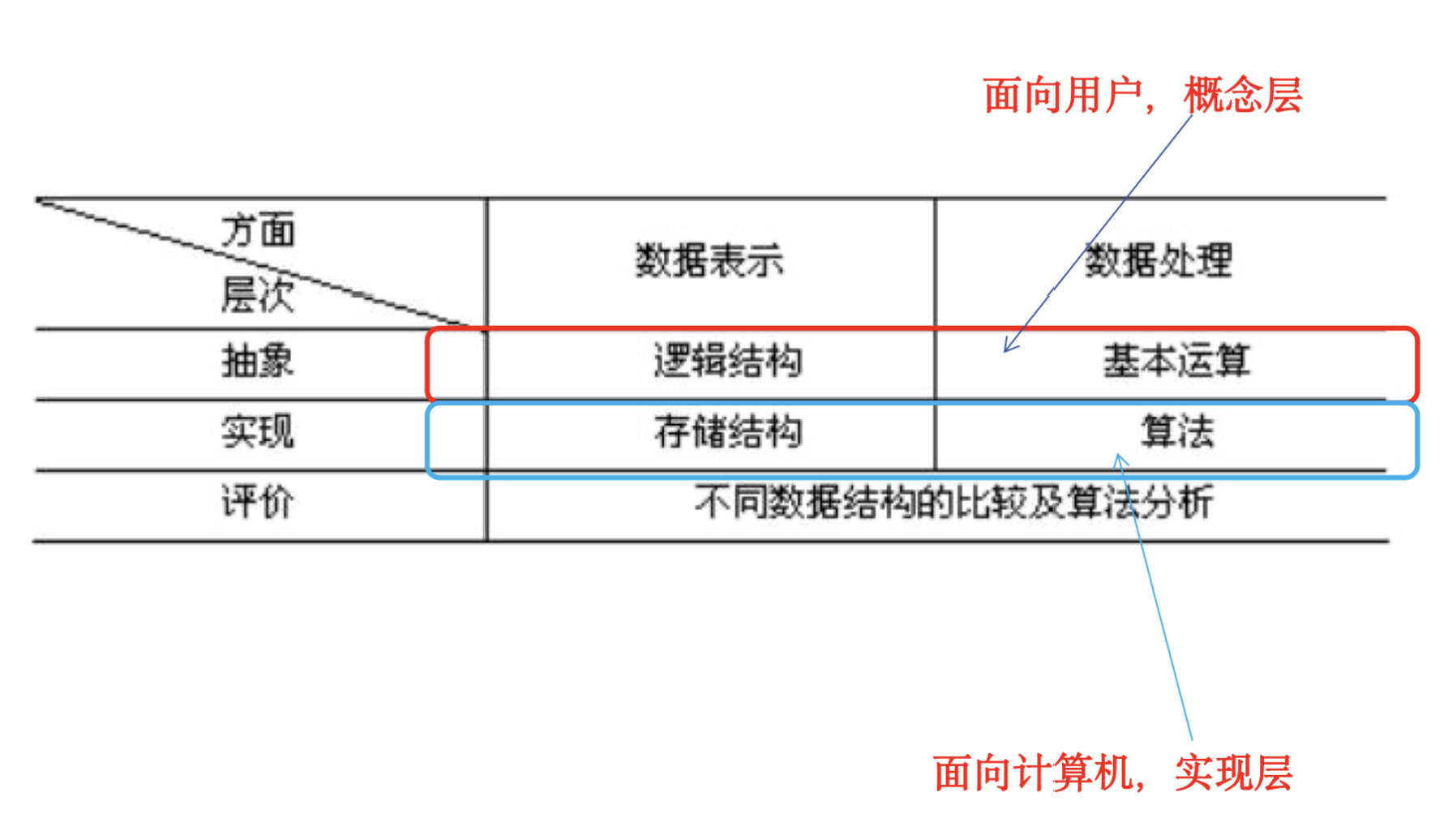
逻辑结构,存储结构及数据运算的含义及其相互关系
算法评价标准:正确性、可读性、健壮性、效率与存储量需求、支持分布式和并行处理的算法在大数据场景下更有优势。
Chapter2 线性表
2.2链表
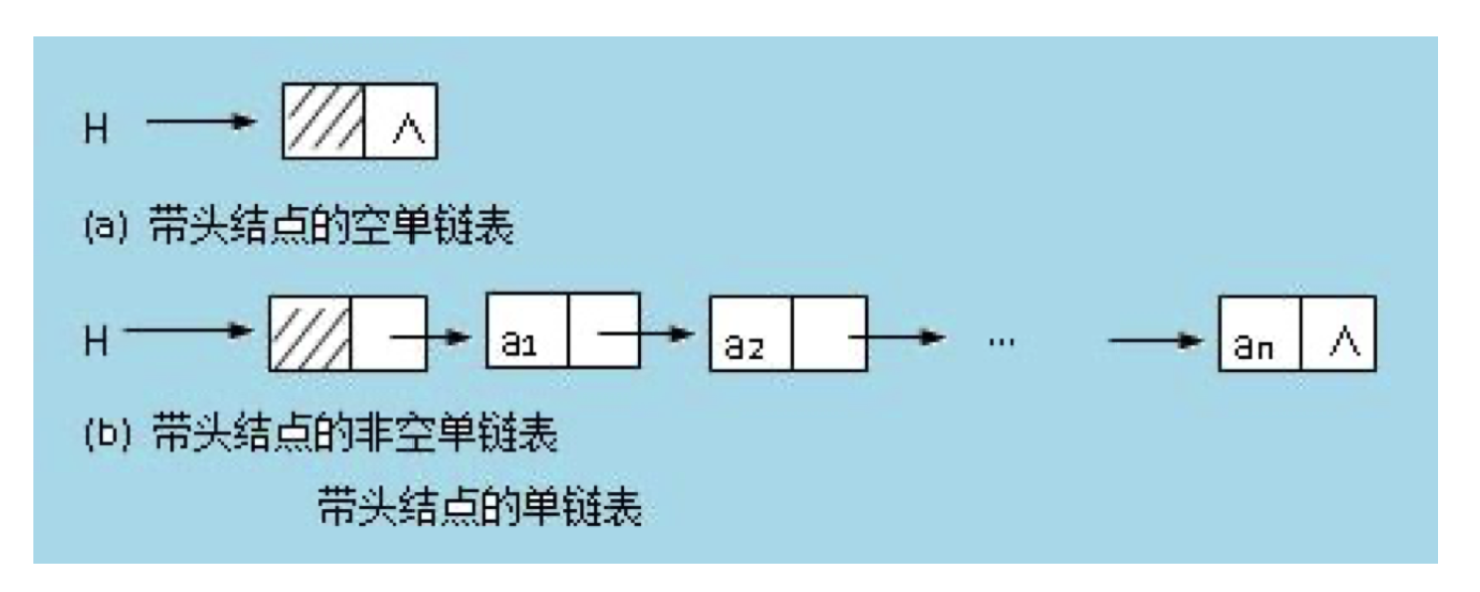
头节点的使用:头节点的指针域指向第一个数据节点的地址
Chapter3 栈、队列
3.1 栈
3.1.1 顺序栈
非空栈中的栈顶指针top来指向栈顶元素的下一个位置 ;
空栈时top = base,栈中元素的数量 = top - base;
3.1.2 链栈
3.1.3 应用
括弧匹配检验
中缀表达式:左括号在栈外时优先级最高,在栈内时优先级很 低,仅高于栈外的右括号;
后缀表达式;
尾递归:递归调用出现在函数中的最后一行,并且没有任何局部变量参与最后一行代码的计算。此时支持“尾递归优化”的编程语言就可以在执行尾递归代码时不进行入栈操作;
3.2 队列
3.2.1 顺序队列
队空是front = rear = 0;非空队列头指针始终指向队列头元素,而尾指针始终指向队列尾元素的下一个位置 。
循环队列:解决“假溢出”;判空采用:front == rear;判满采用:少用一个元素空间,当队尾指针加1就会从后面赶上队头指针,这种情况下队满的条件是:(rear+1) % MAXSIZE == front;
3.2.2 链队
Chapter4 串
4.1 串的基本操作
1 2 3 4 5 6 7 Concat(&T, S1, S2);
4.2 串的模式匹配算法
4.2.1 简单模式匹配算法Brute Force
逐个遍历字符串的每个字母,并逐个检查从它开始的长为len个的字符是否匹配;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int Index (SString S, SString T, int pos) {1 ;while (i <= S[0 ] && j <= T[0 ]) {if (S[i] == T[j]) { else { 2 ;1 ;if (j > T[0 ]) return i-T[0 ];else return 0 ;
最好情况下平均时间复杂度为$O(m + n)$,最坏情况下为$O(m * n)$。
4.2.2 KMP算法
见KMP算法 。
Chapter5 数组与广义表
5.1 数组
数组是线性表的扩展,其数据元素本身也是线性表;
数组中各元素都具有统一的类型;
5. 2 矩阵的压缩存储
5.2.1 对称矩阵
5.2.2 带状矩阵
5.2.3 随机稀疏矩阵
(1)顺序存储方法:三元表法
5.3 广义表
广义表是由零个或多个原子或者子表组成的有限序列;
原子:逻辑上不能再分解的元素;
子表:作为广义表中元素的广义表;
广义表中的元素全部为原子时即为线性表,线性表是广义表的特例,广义表是线性表的推广;
一般用大写字母表示广义表的名称,用小写字母表示原子;
表的长度:表中的(第一层)元素个数;
表的深度:表中元素的最深嵌套层数;
表头:表中的第一个元素;
表尾:除第一个元素外,剩余元素构成的广义表 。 任何一个非空广义表的表尾必定仍为广义表;
Chapter 6 树和二叉树
6.1 树
6.2 二叉树
6.3 线索二叉树
如果无左孩子,那利用左孩子指针指向直接前驱节点;如果无右孩子,那利用右孩子指针指向直接后继节点;
6.4 树和森林
6.4.1 树转化为二叉树
在所有兄弟结点之间加一条连线;
对每个结点,除了保留与其长子的连线外,去掉该结点与其他孩子的连线;
以根为轴心将整棵树顺时针转45度;
6.4.2 森林转化为二叉树
先将森林的每一个树转化为二叉树;
从后一棵树开始,将后一棵树作为前一棵树的右子;
6.4.3 二叉树转化为树/森林
把双亲节点的左孩子的右孩子、右孩子的右孩子、……和双亲节点连接起来;
删除所有双亲节点与右孩子的连线;
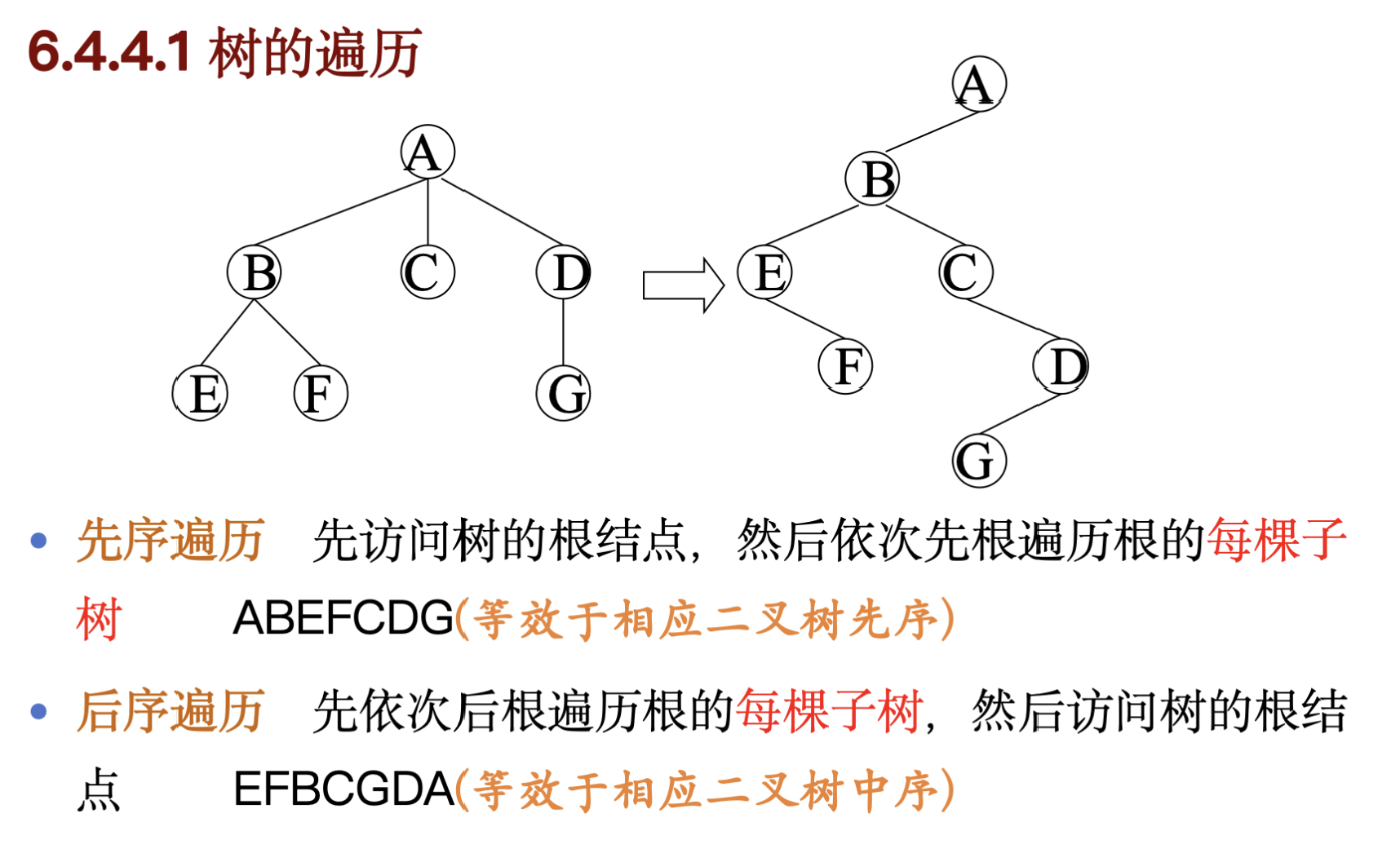
6.4.4 树的遍历
6.4.5 森林的遍历
先序遍历:逐棵先序遍历每棵子树/对应二叉树的先序遍历;
中序遍历:逐棵中序遍历每棵子树/对应二叉树的中序遍历;
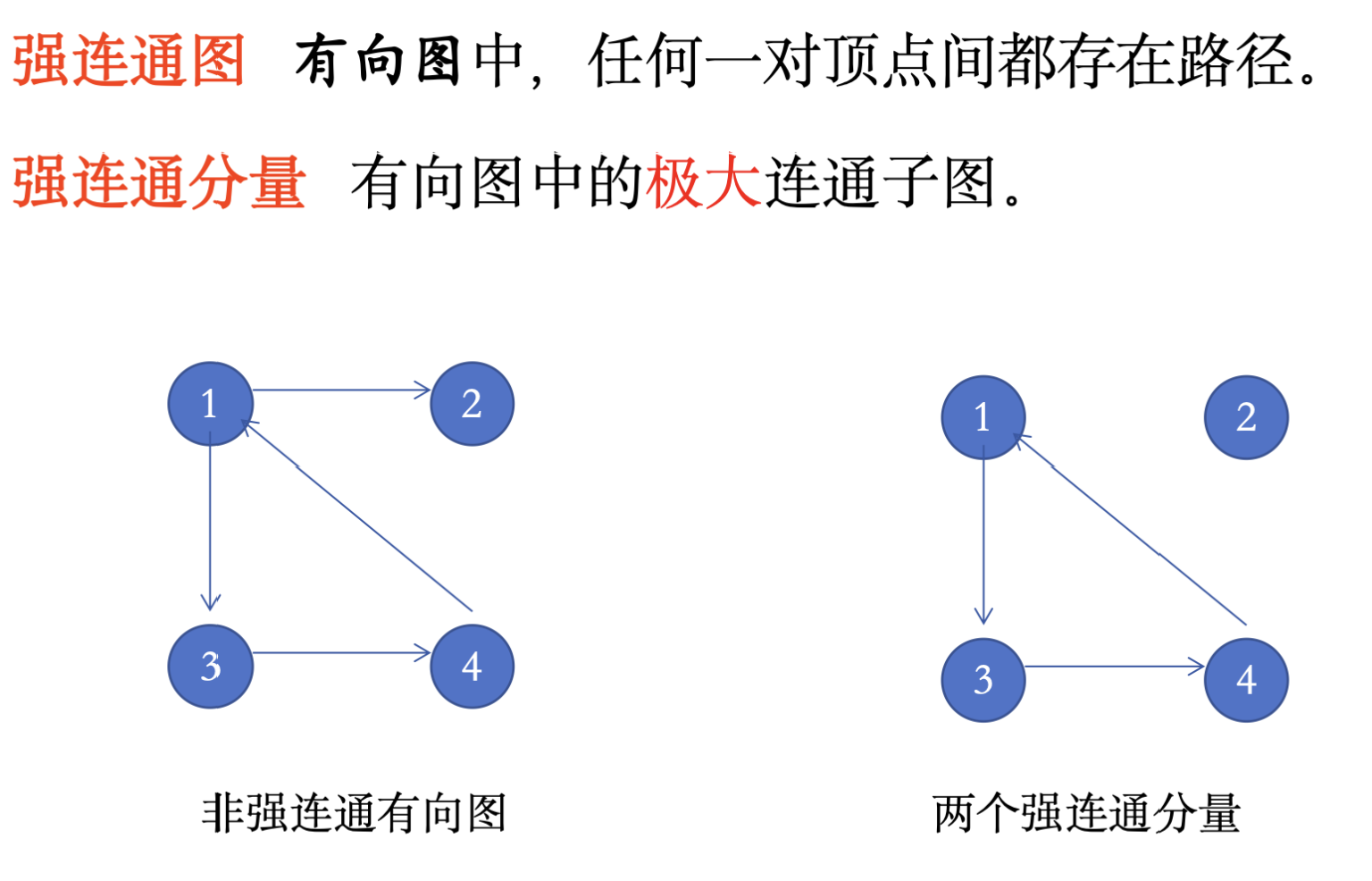
Chapter7 图
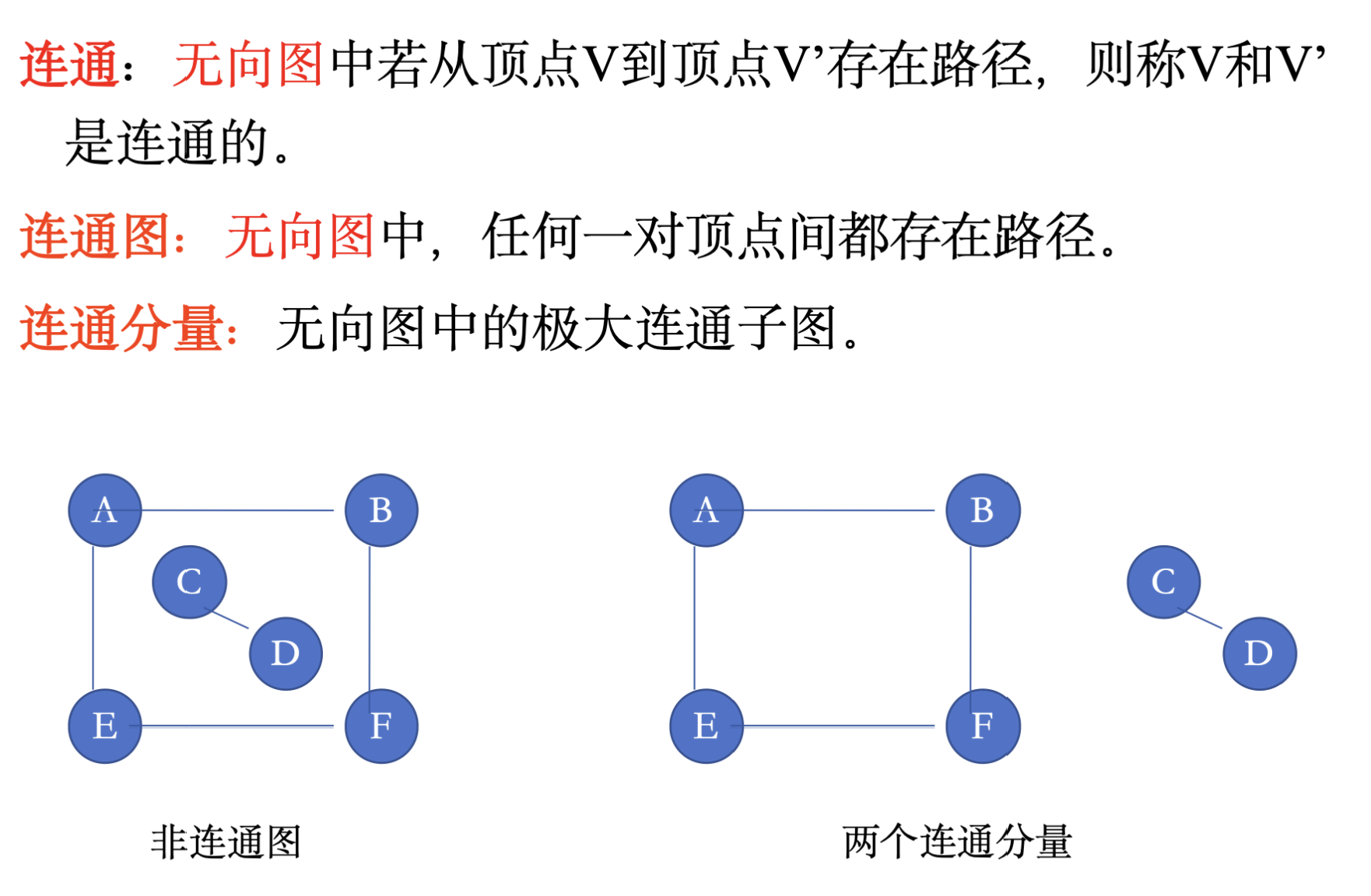
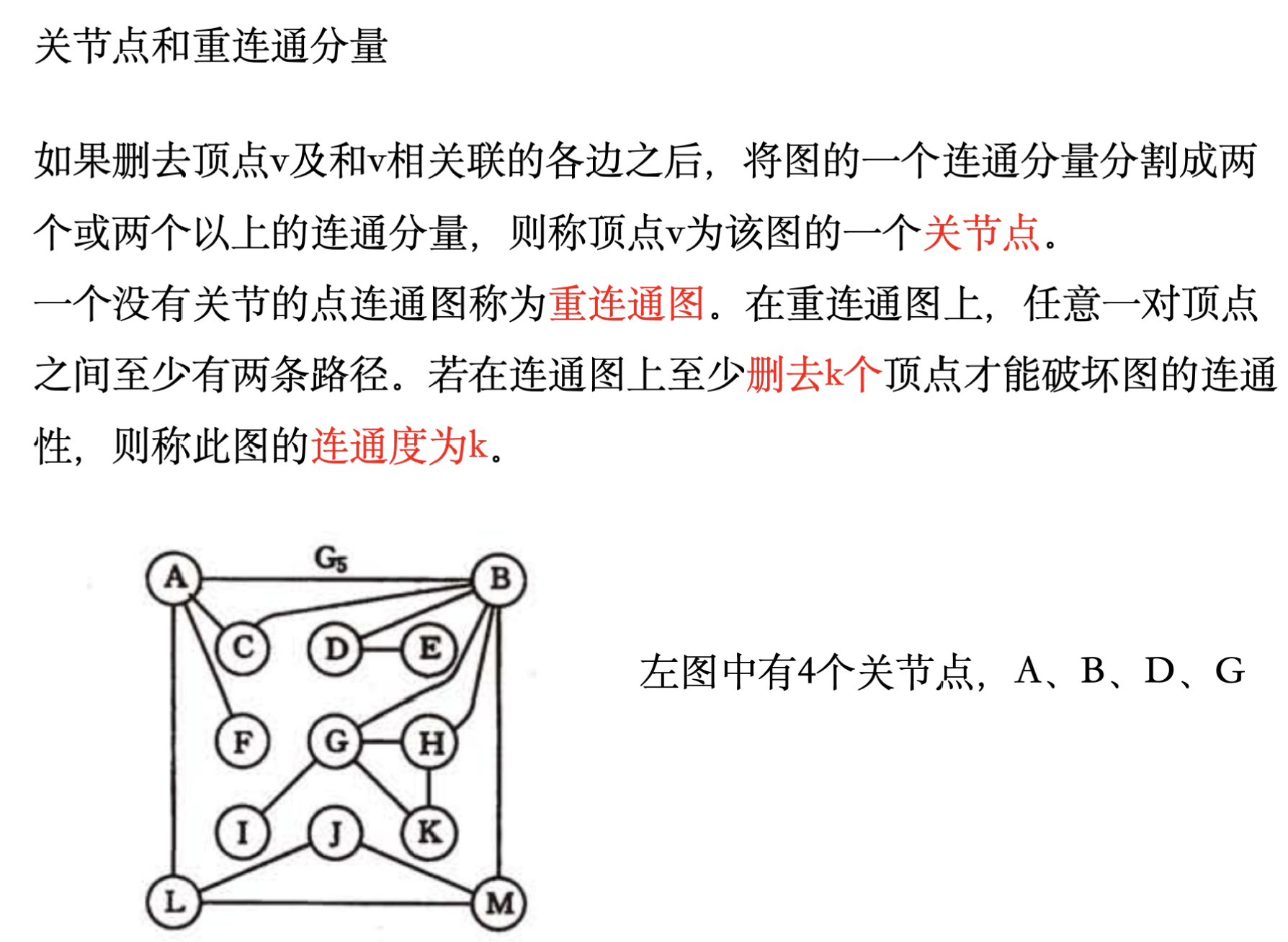
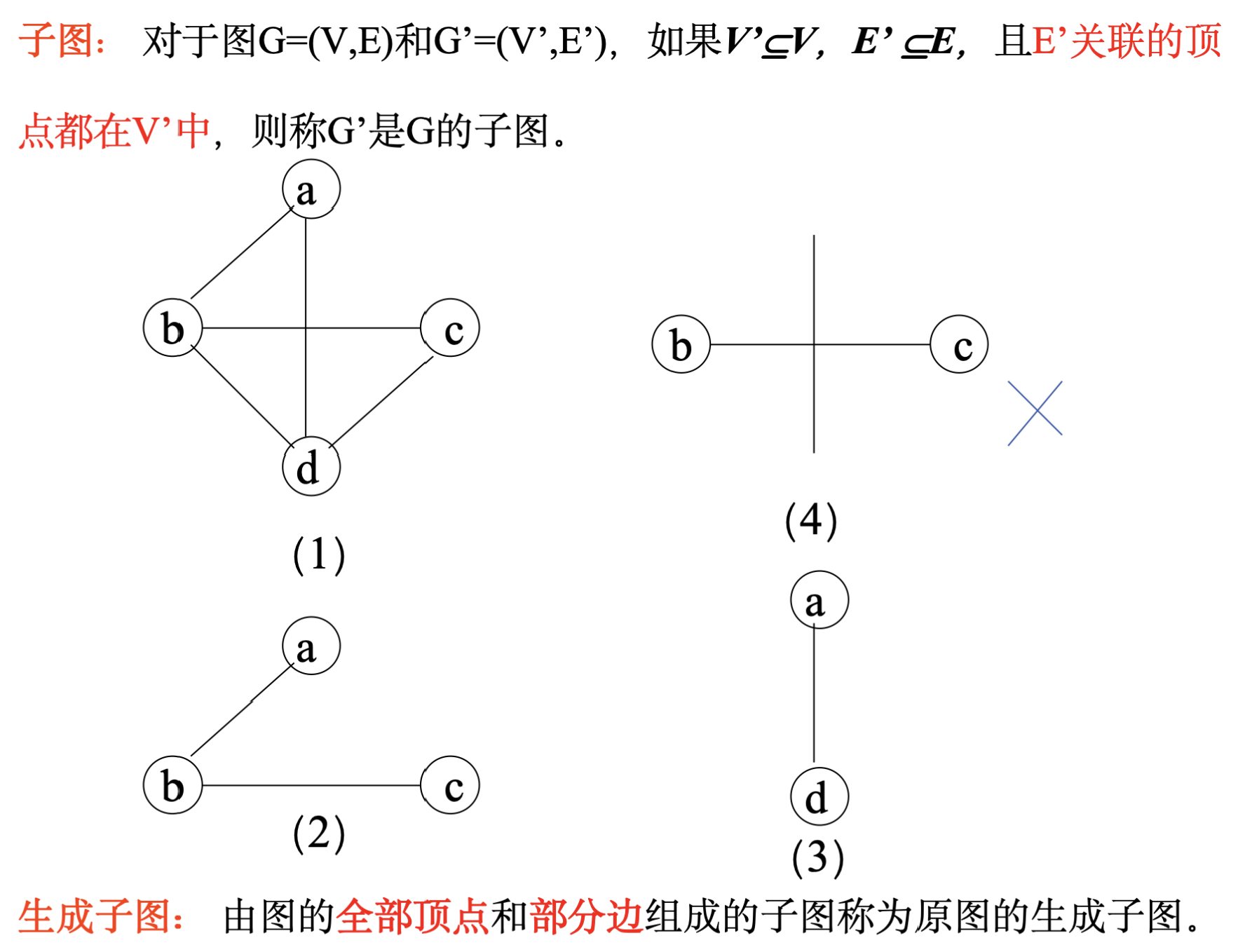
7.1 一些基本概念:
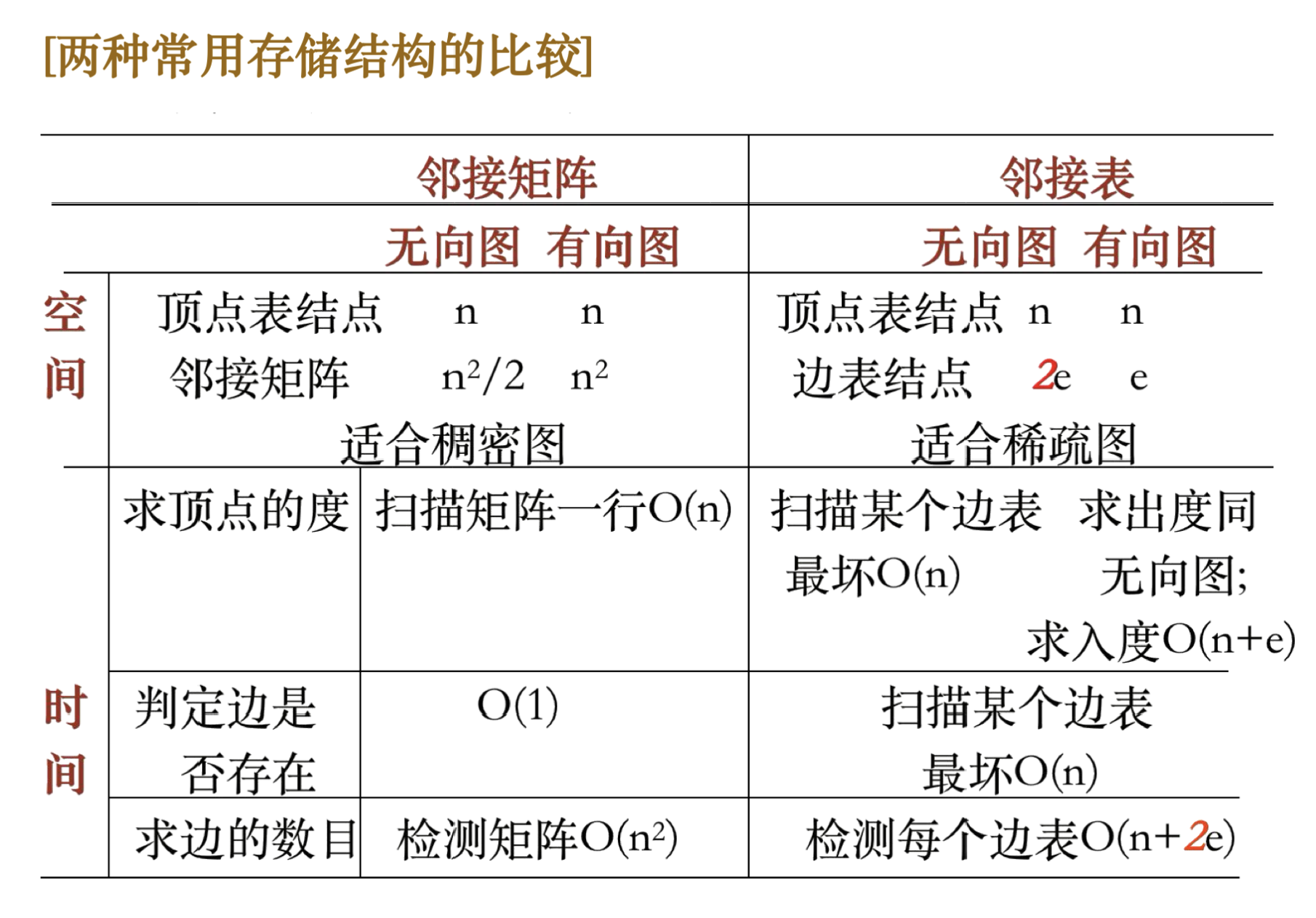
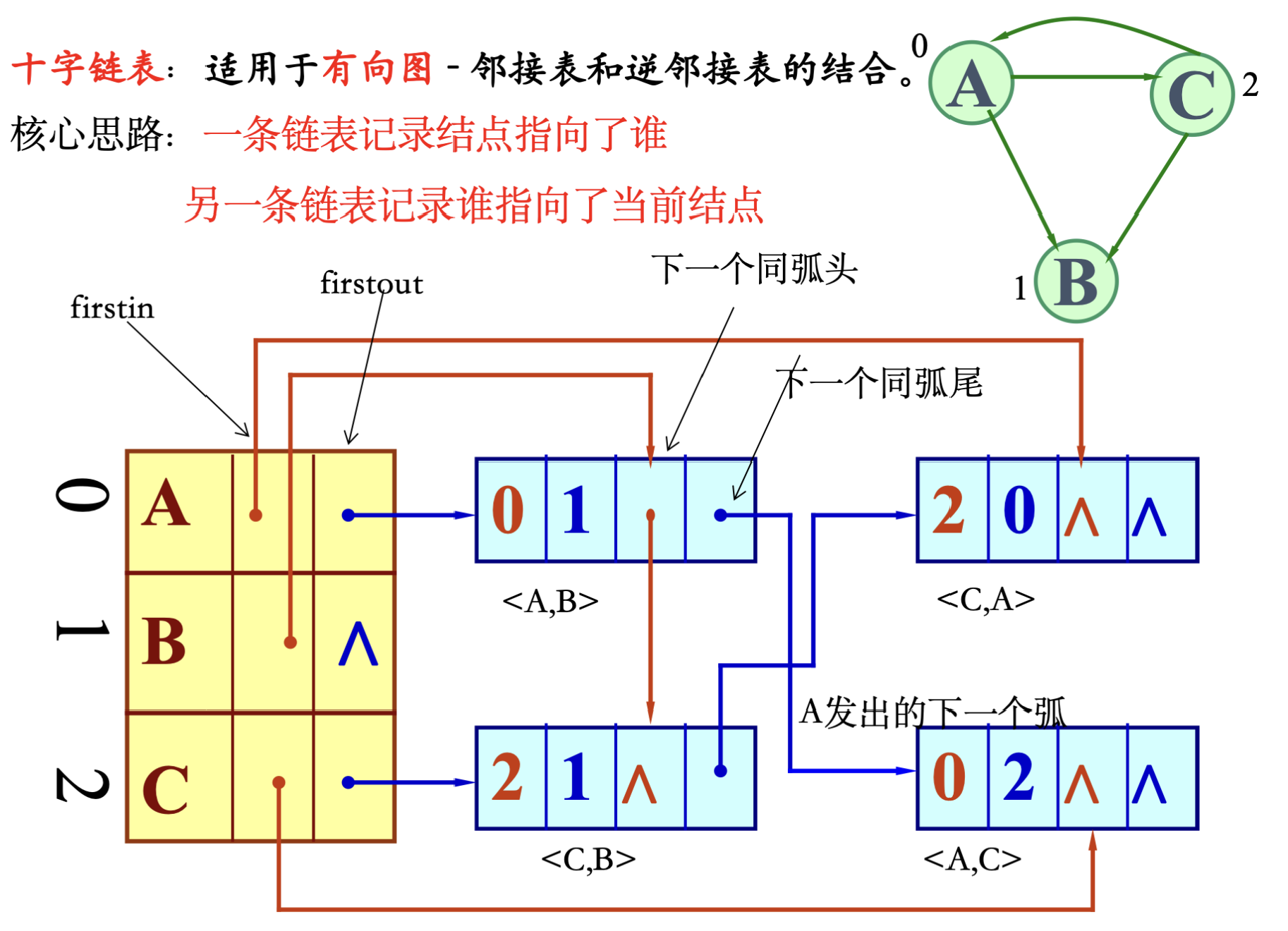
7.2 图的基本存储结构
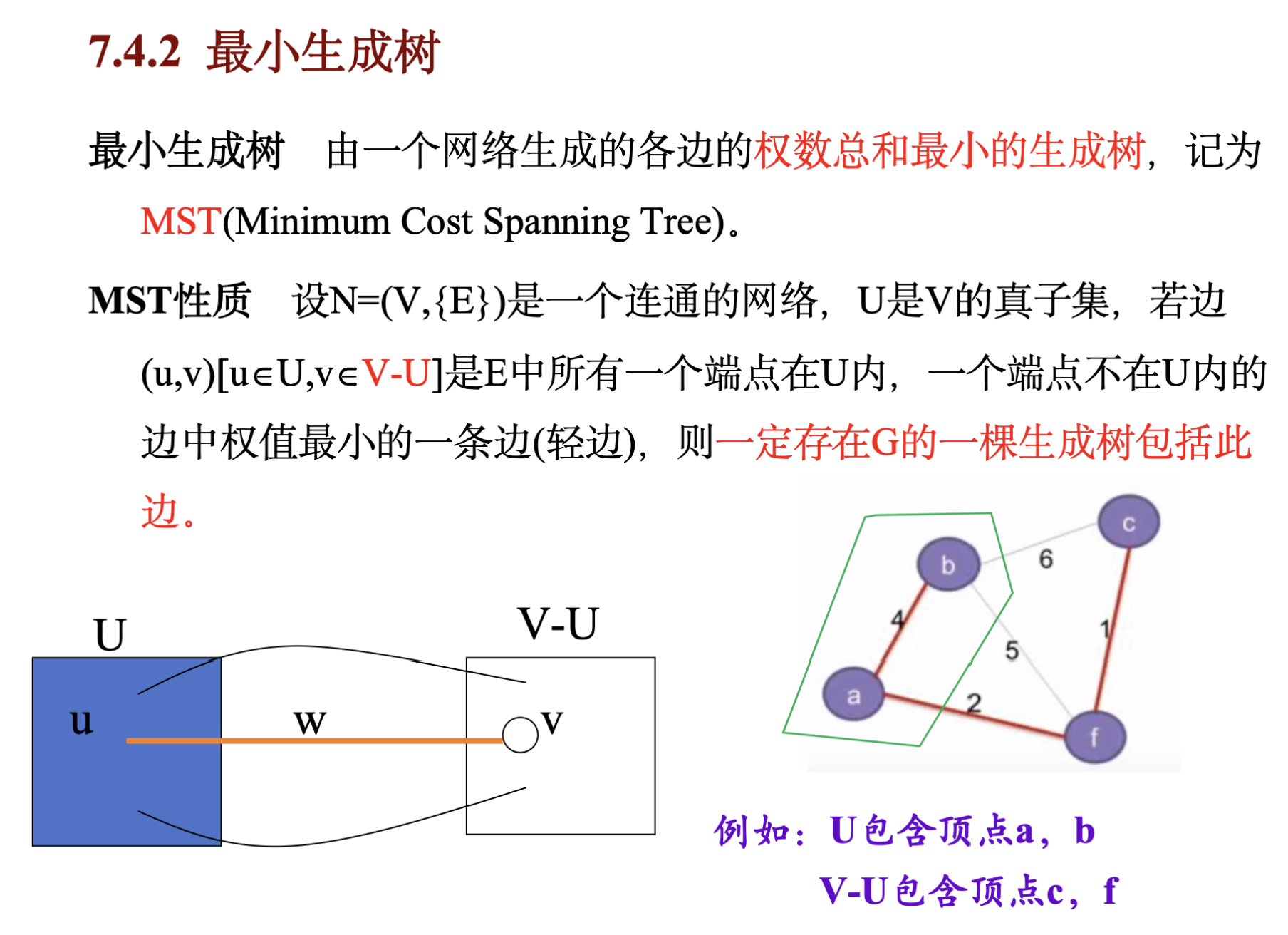
7.3 最小生成树
7.4 拓扑排序
7.4.1 无前驱的顶点优先算法
7.4.2 无后继的顶点优先
7.5 关键路径
7.5.1 AOE网
7.5.2 关键术语
7.5.3 求解方法
希望求解关键路径,即源点到汇点最长的路径;
对于事件
最早发生时间:源点为0,其他点 = Max(源点到该事件的路径长度);
最迟发生时间:(倒着算)汇点 = 最早发生时间,其他点 = Min(下一个点最早发生时间 - 边权);(为了保证下一个事件能最早发生,所以取最小的那个时间)
对于活动
最早发生时间:等于起始点事件的最早发生时间;
最迟发生时间:等于终点时间的最迟发生时间 - 边权;
Chapter9 查找
9.1 顺序查找
1 2 3 4 5 6 int Search_Seq (SSTable ST, KeyType key) {0 ].key = key; for (int i = ST.length; key != ST.elem[i].key; i--) {return i;
监视哨的好处:无需进行边界检测,提高效率;
平均查找长度ASL:
(1)成功ASL:$(1 + n)* n /2 * \frac{1}{n} = \frac{n+1}{2}$;
(2)失败ASL:$1 + n$;
9.2 折半查找
9.2.1 构建步骤
(1)mid = (1 + n)/2 作为根节点,(1 + mid - 1)/2 作为它的左孩子,(mid + 1 + n)/2 作为右孩子;
9.2.2 平均查找长度ASL
成功ASL:待查找的节点在第$x$层,需要比较的次数就是$x$,加权求和即可;
9.3 二叉排序树
9.3.1 构建步骤
(1)给定序列,第一个节点作为根节点;
9.3.2 调整(删除节点*p)
(1)p是叶子结点:修改双亲指针即可;左子树中最右或者右子树中最左 的节点代替它。
9.4 平衡二叉树
9.4.1 维持平衡操作
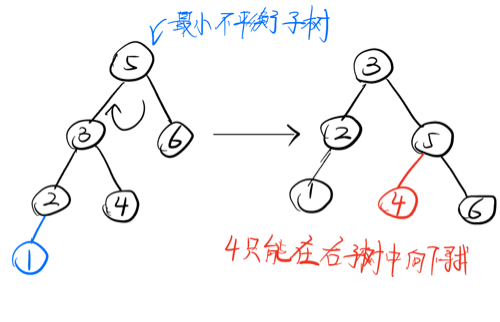
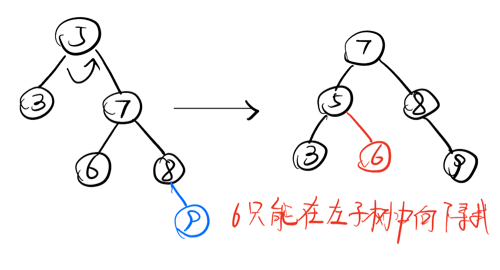
最小不平衡子树 :最下往上,第一个出现左右子树深度之差 > 1的节点。
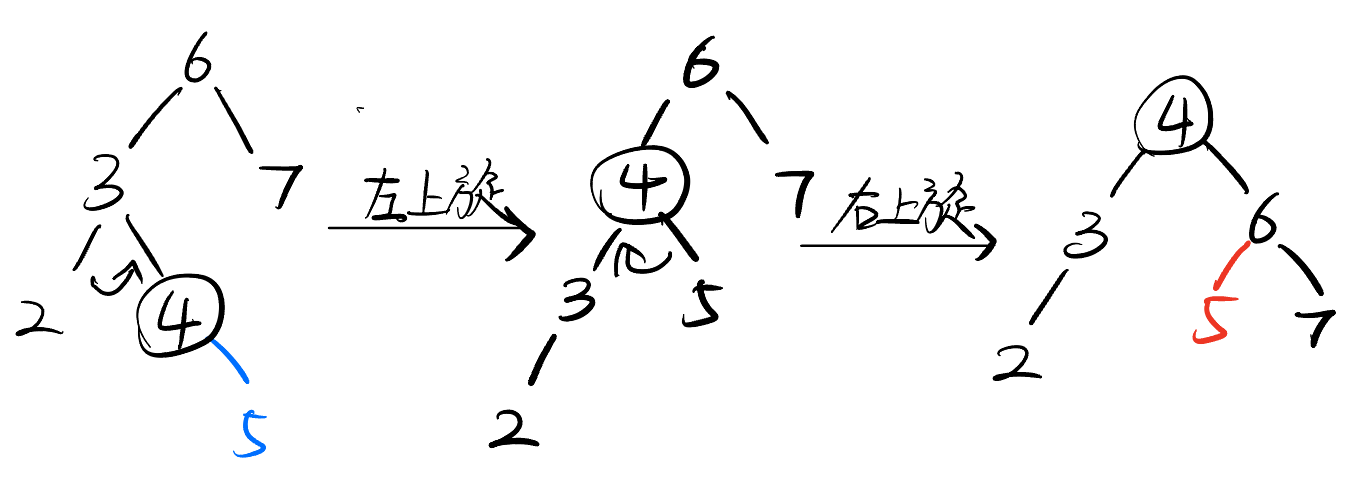
1. LL型
新插入的节点在最小不平衡子树的左孩子的左子树;
调整方法:左孩子向右上旋转;
2. RR型
新插入的节点在最小不平衡子树的右孩子的右子树;
调整方法:右孩子向左上旋转;(和LL型刚好相反)
3.LR型
新插入的节点在最小不平衡子树的左孩子的右子树;
调整方法:左孩子的右子树先左上旋,再右上旋;
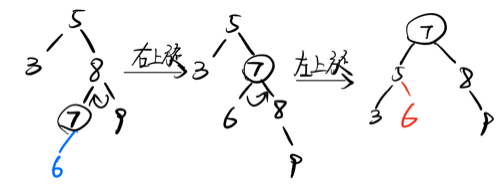
4. RL型
新插入的节点在最小不平衡子树的右孩子的左子树;
调整方法:右孩子的左子树先右上旋,再左上旋;(和LR型刚好相反)
9.5 B-树
B-树是一种多叉平衡搜索树。
对于$m$叉树,要求:
每个节点最多有$m$个分支,$m-1$个元素;
根节点最少有$2$个分支,$1$个元素;
其他节点最少有$\left \lceil \frac{m}{2} \right \rceil$个分支,$\left \lceil \frac{m}{2} \right \rceil - 1$个节点;
9.5.1 B-树的构建和插入
先查找到插入到位置进行插入;
如果没有上溢出,无需调整;
如果发生上溢出,将第$\left \lceil \frac{m}{2} \right \rceil$个元素(中间元素)向上移动,两边分裂(直至不发生上溢出);
9.5.2 B-树的删除
B-树的根结点可以始终置于内存中;其余非叶结点放置在外存上,每一结点可作为一个读取单位(页/块);
9.6 B+树
Chapter 10 内部排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 #include <iostream> #include <vector> #include <algorithm> #define MAXSIZE 20 using namespace std;typedef int KeyType;typedef struct {+1 ]; int length;void CinList (SqList &L) for (int i = 1 ; i <= L.length; i++) {void CoutList (SqList L) for (int i = 1 ; i <= L.length; i++) {" " ;void InsertSort (SqList &L) for (int i = 2 ; i <= L.length; i++) { if (L.r[i] < L.r[i - 1 ]) {0 ] = L.r[i]; 1 ]; int j;for (j = i - 2 ; L.r[0 ] < L.r[j]; j--) {1 ] = L.r[j]; 1 ] = L.r[0 ]; void ShellSort (SqList &L) void BubbleSort (SqList &L) bool isSorted = true ;for (int i = 0 ; i < L.length - 1 && isSorted; i++) { false ;for (int j = 1 ; j < L.length - i; j++) {if (L.r[j] > L.r[j + 1 ]) { 0 ] = L.r[j];1 ];1 ] = L.r[0 ]; true ; int Partition (SqList &L, int low, int high) 0 ] = L.r[low]; while (low < high) { while (low < high && L.r[high] >= pivotkey) { while (low < high && L.r[low] <= pivotkey) { 0 ]; return low; void Qsort (SqList &L,int low, int high) if (low < high) {int pivotloc = Partition (L, low, high); Qsort (L, low, pivotloc - 1 );Qsort (L, pivotloc + 1 , high); void QuickSort (SqList &L) Qsort (L, 1 , L.length);void SelectSort (SqList &L) for (int i = 1 ; i <= L.length - 1 ; i++) { int k = i; for (int j = i + 1 ; j <= L.length; j++) { if (L.r[j] < L.r[k]) {if (i != k) {0 ] = L.r[i];0 ];void HeapAdjust (SqList &L, int root, int end) 0 ] = L.r[root]; for (int j = 2 * root; j <= end && j + 1 <= end; j *= 2 ) {if (L.r[j] < L.r[j + 1 ]) {if (L.r[0 ] >= L.r[j]) {break ; 0 ];void HeapSort (SqList &L) for (int i = L.length / 2 ; i > 0 ; i--) { HeapAdjust (L, i, L.length);for (int i = L.length; i > 1 ; i--) {0 ] = L.r[1 ];1 ] = L.r[i];0 ]; HeapAdjust (L, 1 , i - 1 ); void Merge (int Source[], int * Dest, int left, int mid, int right) int i = left, j = mid + 1 , k = left;while (i <= mid && j <= right) {if (Source[i] < Source[j]) { else {while (i <= mid) {while (j <= mid) {void MSort (int Source[], int * Dest, int start, int end) if (start == end) { else {int mid = (start + end) / 2 ;int Temp[MAXSIZE]; MSort (Source, Temp, start, mid); MSort (Source, Temp, mid + 1 , end); Merge (Temp, Dest, start, mid, end); void MergeSort (SqList &L) MSort (L.r, L.r, 1 , L.length);void BucketSort (SqList &L) 1 ], minVal = L.r[1 ];for (int i = 2 ; i <= L.length; i++) {if (L.r[i] > maxVal) maxVal = L.r[i];if (L.r[i] < minVal) minVal = L.r[i];int bucketCount = L.length;buckets (bucketCount);double range = (double )(maxVal - minVal + 1 ) / bucketCount; for (int i = 1 ; i <= L.length; i++) {int index = (L.r[i] - minVal) / range; if (index >= bucketCount) index = bucketCount - 1 ;push_back (L.r[i]);for (int i = 0 ; i < bucketCount; i++) {sort (buckets[i].begin (), buckets[i].end ()); int idx = 1 ;for (int i = 0 ; i < bucketCount; i++) {for (KeyType val : buckets[i]) {void CountSort (SqList &L) int maxVal = L.r[1 ], minVal = L.r[L.length];for (int i = 2 ; i <= L.length; i++) {if (L.r[i] > maxVal) {if (L.r[i] < minVal) {int * C = new int [maxVal - minVal + 1 ]();for (int i = 1 ; i <= L.length; i++) {int k = 1 ;for (int i = minVal; i <= maxVal; i++) {for (int j = 0 ; j < C[i - minVal]; j++) {void RadixSort (SqList &L) int main () CinList (L);CountSort (L);CoutList (L);return 0 ;
Chapter 11 外部排序
11.1 置换选择法
意义是在内存工作区容量的限制下,获得尽可能长的初始归并段 。
5, 20, 26, 46, 31, 25, 16, 51, 17, 28, 1
文件放入内存工作区:5,20,26,46,31;
第一趟:25,20,26,46,31,第一个归并段:5;
第二趟:25,16,26,46,31,第一个归并段:5,20;
第三趟:(不能出最小的16,要出一个比20大的)51,16,26,46,31,第一个归并段:5,20,25;
第四趟:51,16,17,46,31,第一个归并段:5,20,25,26;
第五趟:51,16,17,46,28,第一个归并段:5,20,25,26,31;
第六趟:51,16,17,1,28,第一个归并段:5,20,25,26,31,46;
第七趟:16,17,1,28,第一个归并段:5,20,25,26,31,46,51;
第八趟~第十一趟:(此时剩余待排序文件无法放入第一个归并段,生成第二个归并段)1,16,17,28;
11.2 最佳归并树
最佳归并树即$k$叉(阶)哈夫曼树。设初始归并段为$m$个,进行$k-$路归并。
11.3 败者树
对于初始为升序的归并段进行多路归并,败者树中记录的冠军节点保存的是最小关键字所在的归并段号 ,分支节点保存的是失败者所在的归并段号。